


Sentiment Analysis With Serverless AI
- Tutorial Prerequisites
- Licenses
- Serverless AI Inferencing With Spin Applications
- Creating a New Spin Application
- Supported AI Models
- Application Structure
- Application Configuration
- Source Code
- Additional Functionality
- Static Fileserver Component For The UI
- Add the Front-End
- Key Value Explorer
- Application Manifest
- Building and Deploying Your Spin Application
- Test Locally
- Deploy to Fermyon Cloud
- Testing in Fermyon Cloud
- Visit Fermyon Cloud UI
- Integrating Custom Domain and Storage
- Conclusion
- Next Steps
Artificial Intelligence (AI) Inferencing performs well on GPUs. However, GPU infrastructure is both scarce and expensive. This tutorial will show you how to use Fermyon Serverless AI to quickly build advanced AI-enabled serverless applications that can run on Fermyon Cloud. Your applications will benefit from 50 millisecond cold start times and operate 100x faster than other on-demand AI infrastructure services. Take a quick look at the video below to learn about executing inferencing on LLMs with no extra setup.
In this tutorial we will:
- Update Spin (and dependencies) on your local machine
- Create a Serverless AI application
- Learn about the Serverless AI SDK
Tutorial Prerequisites
Spin
You will need to install the latest version of Spin. This tutorial requires Spin 3.0 or greater.
If you already have Spin installed, check what version you are on and upgrade if required.
Dependencies
The above installation script automatically installs the latest SDKs for Rust (which will enable us to write Serverless AI applications in Rust). However, some of the Serverless AI examples are written using TypeScript/Javascript, Python and TinyGo. To enable Serverless AI functionality via TypeScript/Javascript, Python and TinyGo, please ensure you have the latest TypeScript/JavaScript, Python or TinyGo template installed:
TypeScript/Javascript
$ spin templates install --git https://github.com/spinframework/spin-js-sdk --upgrade
Python
Ensure that you have Python 3.10 or later installed on your system. You can check your Python version by running:
python3 --version
If you do not have Python 3.10 or later, you can install it by following the instructions here.
Some of the Serverless AI examples are written using Python. To enable Serverless AI functionality via Python, please ensure you have the latest Python template installed:
$ spin templates install --git https://github.com/spinframework/spin-python-sdk --upgrade
TinyGo
Some of the Serverless AI examples are written using TinyGo. To enable Serverless AI functionality via TinyGo, please ensure you have the latest Spin template installed (the following command will make the http-go template available):
$ spin templates install --git https://github.com/spinframework/spin --upgrade
Licenses
This tutorial uses Meta AI’s Llama 2, Llama Chat and Code Llama models you will need to visit Meta’s Llama webpage and agree to Meta’s License, Acceptable Use Policy, and to Meta’s privacy policy before fetching and using Llama models.
Serverless AI Inferencing With Spin Applications
Now, let’s dive deep into a comprehensive tutorial and unlock your potential to use Fermyon Serverless AI. Note: The full source code with other examples can be found in our Github repo
Creating a New Spin Application
The Rust code snippets below are taken from the Fermyon Serverless AI Examples
Note: please add
/api/...when prompted for the path; this provides us with an API endpoint to query the sentiment analysis component.
$ spin new -t http-rust
Enter a name for your new application: sentiment-analysis
Description: A sentiment analysis API that demonstrates using LLM inferencing and KV stores together
HTTP path: /api/...
The TypeScript code snippets below are taken from the Fermyon Serverless AI Examples
Note: please add
/api/...when prompted for the path; this provides us with an API endpoint to query the sentiment analysis component.
$ spin new -t http-ts
Enter a name for your new application: sentiment-analysis
Description: A sentiment analysis API that demonstrates using LLM inferencing and KV stores together
HTTP path: /api/...
The Python code snippets below are taken from the Fermyon Serverless AI Examples
Note: please add
/api/...when prompted for the path; this provides us with an API endpoint to query the sentiment analysis component.
$ spin new -t http-py
Enter a name for your new application: sentiment-analysis
Description: A sentiment analysis API that demonstrates using LLM inferencing and KV stores together
HTTP path: /api/...
Note: please add
/api/...when prompted for the path; this provides us with an API endpoint to query the sentiment analysis component.
$ spin new -t http-go
Enter a name for your new application: sentiment-analysis
Description: A sentiment analysis API that demonstrates using LLM inferencing and KV stores together
HTTP path: /api/...
Supported AI Models
Fermyon’s Spin and Serverless AI currently support:
- Meta’s open source Large Language Models (LLMs) Llama, specifically the
llama2-chatandcodellama-instructmodels (see Meta Licenses section above). - SentenceTransformers’ embeddings models, specifically the
all-minilm-l6-v2model.
Application Structure
Next, we need to create the appropriate folder structure from within the application directory (alongside our spin.toml file). The code below demonstrates the variations in folder structure depending on which model is being used. Once the folder structure is in place, we then fetch the pre-trained AI model for our application:
Note: Optional, but highly recommended, is to use the Spin Cloud GPU component. This offloads inferencing to Fermyon Cloud GPUs, and thus requires a free account to Fermyon Cloud Serverless AI. This would replace the following steps of having to download the three models below.
llama2-chat example download
Ensure you have read the Meta Licenses section before continuing to use Llama models.
Download the the *.safetensors, config.json and tokenizer.json from huggingface and place it in the following structure below. The .spin directory needs to be placed in the root of the Spin project.
tree .spin
.spin
└── ai-models
└── llama
└── llama2-chat
└── <*.safetensors files>
└── config.json
└── tokenizor.json
codellama-instruct example download
Ensure you have read the Meta Licenses section before continuing to use Llama models.
Download the *.safetensors, config.json and tokenizer.json from huggingface and place it in the following structure below.
tree .spin
.spin
└── ai-models
└── llama
└── codellama-instruct
└── <*.safetensors files>
└── config.json
└── tokenizor.json
all-minilm-l6-v2 example download
The following section fetches a specific version of the sentence-transformers model:
$ mkdir -p .spin/ai-models/all-minilm-l6-v2
$ cd .spin/ai-models/all-minilm-l6-v2
$ wget https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2/resolve/7dbbc90392e2f80f3d3c277d6e90027e55de9125/tokenizer.json
$ wget https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2/resolve/0b6dc4ef7c29dba0d2e99a5db0c855c3102310d8/model.safetensors
tree .spin
.spin
└── ai-models
└── all-minilm-l6-v2
├── model.safetensors
└── tokenizer.json
Note: Rather than be limited to a 1:1 relationship between a Spin applications and a downloaded model, if you would like more than just one Spin application to access a specific model (that you have already downloaded) you can create an arbitrary directory (i.e.
~/my-ai-models/) to house your models, and then create a symbolic link to a specific Spin application (i.e.~/application-one/.spin/ai-models):
ln -s ~/my-ai-models/ ~/application-one/.spin/ai-models
Application Configuration
Then, we configure the [component.sentiment-analysis] section of our application’s manifest (the spin.toml file); explicitly naming our model of choice. For example, in the case of the sentiment analysis application, we specify the llama2-chat value for our ai_models configuration, and add a default key-value store:
Note:
[component.sentiment-analysis]contains the name of the component. If you used a different name, when creating the application, this sections name would be different.
[component.sentiment-analysis]
...
ai_models = ["llama2-chat"]
key_value_stores = ["default"]
...
Source Code
Now let’s use the Spin SDK to access the model from our app:
The Rust source code for this sentiment analysis example uses serde. There are a couple of ways to add the required serde dependencies:
- Run
cargo add serde -F deriveandcargo add serde_jsonfrom your Rust application’s home directory (which will automatically update your application’sCargo.tomlfile), or - Manually, edit your Rust application’s
Cargo.tomlfile by adding the following lines beneath theCargo.tomlfile’s[dependencies]section:
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
Once you have added serde, as explained above, modify your src/lib.rs file to match the following content:
use std::str::FromStr;
use anyhow::Result;
use spin_sdk::{
http::{IntoResponse, Json, Params, Request, Response, Router},
http_component,
key_value::Store,
llm::{infer_with_options, InferencingModel::Llama2Chat},
};
use serde::{Deserialize, Serialize};
#[derive(Deserialize)]
pub struct SentimentAnalysisRequest {
pub sentence: String,
}
#[derive(Serialize)]
pub struct SentimentAnalysisResponse {
pub sentiment: String,
}
const PROMPT: &str = r#"\
<<SYS>>
You are a bot that generates sentiment analysis responses. Respond with a single positive, negative, or neutral.
<</SYS>>
<INST>
Follow the pattern of the following examples:
User: Hi, my name is Bob
Bot: neutral
User: I am so happy today
Bot: positive
User: I am so sad today
Bot: negative
</INST>
User: {SENTENCE}
"#;
/// A Spin HTTP component that internally routes requests.
#[http_component]
fn handle_route(req: Request) -> Response {
let mut router = Router::new();
router.any("/api/*", not_found);
router.post("/api/sentiment-analysis", perform_sentiment_analysis);
router.handle(req)
}
fn not_found(_: Request, _: Params) -> Result<impl IntoResponse> {
Ok(Response::new(404, "Not found"))
}
fn perform_sentiment_analysis(
req: http::Request<Json<SentimentAnalysisRequest>>,
_params: Params,
) -> Result<impl IntoResponse> {
// Do some basic clean up on the input
let sentence = req.body().sentence.trim();
println!("Performing sentiment analysis on: {}", sentence);
// Prepare the KV store
let kv = Store::open_default()?;
// If the sentiment of the sentence is already in the KV store, return it
if kv.exists(sentence).unwrap_or(false) {
println!("Found sentence in KV store returning cached sentiment");
let sentiment = kv.get(sentence)?;
let resp = SentimentAnalysisResponse {
sentiment: String::from_utf8(sentiment.unwrap())?,
};
let resp_str = serde_json::to_string(&resp)?;
return Ok(Response::new(200, resp_str));
}
println!("Sentence not found in KV store");
// Otherwise, perform sentiment analysis
println!("Running inference");
let inferencing_result = infer_with_options(
Llama2Chat,
&PROMPT.replace("{SENTENCE}", sentence),
spin_sdk::llm::InferencingParams {
max_tokens: 8,
..Default::default()
},
)?;
println!("Inference result {:?}", inferencing_result);
let sentiment = inferencing_result
.text
.lines()
.next()
.unwrap_or_default()
.strip_prefix("Bot:")
.unwrap_or_default()
.parse::<Sentiment>();
println!("Got sentiment: {sentiment:?}");
if let Ok(sentiment) = sentiment {
println!("Caching sentiment in KV store");
let _ = kv.set(sentence, sentiment.as_str().as_bytes());
}
// Cache the result in the KV store
let resp = SentimentAnalysisResponse {
sentiment: sentiment
.as_ref()
.map(ToString::to_string)
.unwrap_or_default(),
};
let resp_str = serde_json::to_string(&resp)?;
Ok(Response::new(200, resp_str))
}
#[derive(Copy, Clone, Debug)]
enum Sentiment {
Positive,
Negative,
Neutral,
}
impl Sentiment {
fn as_str(&self) -> &str {
match self {
Self::Positive => "positive",
Self::Negative => "negative",
Self::Neutral => "neutral",
}
}
}
impl std::fmt::Display for Sentiment {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
f.write_str(self.as_str())
}
}
impl FromStr for Sentiment {
type Err = String;
fn from_str(s: &str) -> std::result::Result<Self, Self::Err> {
let sentiment = match s.trim() {
"positive" => Self::Positive,
"negative" => Self::Negative,
"neutral" => Self::Neutral,
_ => return Err(s.into()),
};
Ok(sentiment)
}
}
import { Llm, Kv } from "@fermyon/spin-sdk";
import { AutoRouter } from 'itty-router';
interface SentimentAnalysisRequest {
sentence: string;
}
interface SentimentAnalysisResponse {
sentiment: "negative" | "neutral" | "positive";
}
const decoder = new TextDecoder();
const PROMPT = `\
<<SYS>>
You are a bot that generates sentiment analysis responses. Respond with a single positive, negative, or neutral.
<</SYS>>
<INST>
Follow the pattern of the following examples:
Hi, my name is Bob
neutral
I am so happy today
positive
I am so sad today
negative
</INST>
<SENTENCE>
`;
async function performSentimentAnalysis(request: Request) {
// Parse sentence out of request
let data = await request.json() as SentimentAnalysisRequest;
let sentence = data.sentence;
console.log("Performing sentiment analysis on: " + sentence);
// Prepare the KV store
let kv = Kv.openDefault();
// If the sentiment of the sentence is already in the KV store, return it
if (kv.exists(sentence)) {
console.log("Found sentence in KV store returning cached sentiment");
return {
status: 200,
body: JSON.stringify({
sentiment: decoder.decode(kv.get(sentence)),
} as SentimentAnalysisResponse),
};
}
console.log("Sentence not found in KV store");
// Otherwise, perform sentiment analysis
console.log("Running inference");
let options: Llm.InferencingOptions = { maxTokens: 6 };
let inferenceResult = Llm.infer(
Llm.InferencingModels.Llama2Chat,
PROMPT.replace("<SENTENCE>", sentence),
options
);
console.log(
`Inference result (${inferenceResult.usage.generatedTokenCount} tokens): ${inferenceResult.text}`
);
let sentiment = inferenceResult.text.split(/\s+/)[0]?.trim();
// Clean up result from inference
if (
sentiment === undefined ||
!["negative", "neutral", "positive"].includes(sentiment)
) {
sentiment = "neutral";
console.log("Invalid sentiment, marking it as neutral");
}
// Cache the result in the KV store
console.log("Caching sentiment in KV store");
kv.set(sentence, sentiment);
return new Response(JSON.stringify({
sentiment,
} as SentimentAnalysisResponse), { headers: { "Content-Type": "application/json" }});
}
let router = AutoRouter();
// Map the route to the handler
router.post("/api/sentiment-analysis", async (req) => {
console.log(`${new Date().toISOString()} POST /sentiment-analysis`);
return await performSentimentAnalysis(req);
});
//@ts-ignore
addEventListener('fetch', async (event: FetchEvent) => {
event.respondWith(router.fetch(event.request));
});
from spin_sdk import http, llm, key_value
from spin_sdk.http import Request, Response
import json
PROMPT="""<<SYS>>
You are a bot that generates sentiment analysis responses. Respond with a single positive, negative, or neutral.
<</SYS>>
[INST]
Follow the pattern of the following examples:
User: Hi, my name is Bob
Bot: neutral
User: I am so happy today
Bot: positive
User: I am so sad today
Bot: negative
[/INST]
User: """
class IncomingHandler(http.IncomingHandler):
def handle_request(self, request: Request) -> Response:
# Extracting the sentence from the request_body
request_body=json.loads(request.body)
sentence=request_body["sentence"].strip()
print("Performing sentiment analysis on: " + sentence)
# Open the default KV store
store = key_value.open_default()
# Check if the sentence is already in the KV store
if store.exists(sentence) is False:
result=llm.infer("llama2-chat", PROMPT+sentence).text
print("Raw result: " + result)
sentiment = get_sentiment_from_sentence(result)
print("Storing result in the KV store")
store.set(sentence, str.encode(sentiment))
else:
sentiment = store.get(sentence).decode()
print("Found a cached result")
response_body=json.dumps({"sentiment": sentiment})
return Response(200,
{"content-type": "application/json"},
bytes(response_body, "utf-8"))
def get_sentiment_from_sentence(sentence) -> str:
words = sentence.lower().split()
sentiments = ["positive", "negative", "neutral"]
result = next((word for word in sentiments if word in words), None)
if result is not None:
return result
else:
print("Inconclusive, returning 'neutral'")
return "neutral"
package main
import (
"encoding/json"
"fmt"
"net/http"
"strings"
spinhttp "github.com/fermyon/spin/sdk/go/v2/http"
"github.com/fermyon/spin/sdk/go/v2/kv"
"github.com/fermyon/spin/sdk/go/v2/llm"
)
type sentimentAnalysisRequest struct {
Sentence string
}
type sentimentAnalysisResponse struct {
Sentiment string
}
const prompt = `\
You are a bot that generates sentiment analysis responses. Respond with a single positive, negative, or neutral.
Hi, my name is Bob
neutral
I am so happy today
positive
I am so sad today
negative
<SENTENCE>
`
func init() {
spinhttp.Handle(func(w http.ResponseWriter, r *http.Request) {
router := spinhttp.NewRouter()
router.POST("/api/sentiment-analysis", performSentimentAnalysis)
router.ServeHTTP(w, r)
})
}
func performSentimentAnalysis(w http.ResponseWriter, r *http.Request, ps spinhttp.Params) {
var req sentimentAnalysisRequest
if err := json.NewDecoder(r.Body).Decode(&req); err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
fmt.Printf("Performing sentiment analysis on: %q\n", req.Sentence)
// Open the KV store
store, err := kv.OpenStore("default")
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
defer store.Close()
// If the sentiment of the sentence is already in the KV store, return it
exists, err := store.Exists(req.Sentence)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
if exists {
fmt.Println("Found sentence in KV store returning cached sentiment")
value, err := store.Get(req.Sentence)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
res := sentimentAnalysisResponse{
Sentiment: string(value),
}
if err := json.NewEncoder(w).Encode(res); err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
return
}
fmt.Println("Sentence not found in KV store")
// Otherwise, perform sentiment analysis
fmt.Println("Running inference")
params := &llm.InferencingParams{
MaxTokens: 10,
Temperature: 0.5,
}
result, err := llm.Infer("llama2-chat", strings.Replace(prompt, "<SENTENCE>", req.Sentence, 1), params)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
fmt.Printf("Inference result (%d tokens): %s\n", result.Usage.GeneratedTokenCount, result.Text)
var sentiment string
if fields := strings.Fields(result.Text); len(fields) > 0 {
sentiment = fields[0]
}
// Cache the result in the KV store
fmt.Println("Caching sentiment in KV store")
store.Set(req.Sentence, []byte(sentiment))
res := &sentimentAnalysisResponse{
Sentiment: sentiment,
}
if err := json.NewEncoder(w).Encode(res); err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
}
func main() {}
Additional Functionality
This application also includes two more components, a key/value explorer and static-fileserver component. Let’s quickly go ahead and create those (letting Spin do all of the scaffolding for us).
Static Fileserver Component For The UI
We use the spin add command to add the new static-fileserver that we will name ui:
$ spin add -t static-fileserver
Enter a name for your new component: ui
HTTP path [/static/...]: /...
Directory containing the files to serve [assets]: assets
Add the Front-End
We can add a webpage that asks the user for some text and does the sentiment analysis on it. In your assets folder, create two files dynamic.js and index.html.
Here’s the code snippet for index.html
<!DOCTYPE html>
<html data-theme="cupcake">
<head>
<title>Sentiment Analyzer</title>
<meta name="description" content="Perform sentiment analysis" />
<!-- Tailwind and Daisy UI -->
<link
href="https://cdn.jsdelivr.net/npm/daisyui@3.2.1/dist/full.css"
rel="stylesheet"
type="text/css"
/>
<script src="https://cdn.tailwindcss.com?plugins=typography"></script>
<!-- Import script to make page dynamic -->
<script src="dynamic.js"></script>
</head>
<body class="bg-base-200">
<div id="alert" class="fixed top-20 inset-x-0 w-1/2 mx-auto"></div>
<div class="flex flex-col min-h-screen">
<div
class="sticky top-0 z-30 flex h-16 w-full justify-center bg-opacity-90 backdrop-blur transition-all duration-100 bg-base-100 text-base-content shadow-md"
>
<nav class="navbar w-full">
<div class="flex-1">
<a href="/" class="btn btn-ghost text-4xl font-bold"
>Sentiment Analyzer</a
>
</div>
<div class="flex-none">
<a href="" class="btn btn-warning">Restart</a>
</div>
</nav>
</div>
<main class="mx-auto my-10 prose">
<p>
This Sentiment Analyzer is a demonstration of how you can use Fermyon
Serverless AI to easily make an AI-powered API. When you type in a
sentence it is sent to a Spin app running in the Fermyon Cloud,
inferencing is performed using the Fermyon serverless AI feature, and
the response is cached in a Fermyon key/value store.
</p>
<p>
Note that LLM's are not perfect and the sentiment analysis performed
by this application is not guaranteed to be perfect.
</p>
<p>
To get started type a sentence below and press
<kbd class="kbd kbd-sm">enter</kbd>.
</p>
<div class="flex flex-col gap-8 w-full">
<input
id="sentence-input"
type="text"
placeholder="Type the sentence you want to analyze here"
class="input w-full"
/>
<div>
<button class="btn btn-primary" onclick="newCard()">Analyze</button>
</div>
</div>
</main>
</div>
</body>
</html>
Here’s the code snippet for dynamic.js
// Listen for the Enter key being pressed
document.addEventListener("keydown", function (event) {
if (event.keyCode === 13) {
newCard();
}
});
var globalCardCount = 0;
var runningInference = false;
function newCard() {
if (runningInference) {
console.log("Already running inference, please wait...");
setAlert("Already running inference, please wait...");
return;
}
var inputElement = document.getElementById("sentence-input");
var sentence = inputElement.value;
if (sentence === "") {
console.log("Please enter a sentence to analyze");
setAlert("Please enter a sentence to analyze");
return;
}
inputElement.value = "";
var cardIndex = globalCardCount;
globalCardCount++;
var newCard = document.createElement("div");
newCard.id = "card-" + cardIndex;
newCard.innerHTML = `
<div class="card bg-base-100 shadow-xl w-full">
<div class="m-4 flex flex-col gap-2">
<div>${sentence}</div>
<div class="flex flex-row justify-end">
<span class="loading loading-dots loading-sm"></span>
</div>
</div>
</div>
`;
document.getElementById("sentence-input").before(newCard);
console.log("Running inference on sentence: " + sentence);
runningInference = true;
fetch("/api/sentiment-analysis", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ sentence: sentence }),
})
.then((response) => response.json())
.then((data) => {
console.log(data);
updateCard(cardIndex, sentence, data.sentiment);
})
.catch((error) => {
console.log(error);
});
}
function updateCard(cardIndex, sentence, sentiment) {
badge = "";
if (sentiment === "positive") {
badge = `<span class="badge badge-success">Positive</span>`;
} else if (sentiment === "negative") {
badge = `<span class="badge badge-error">Negative</span>`;
} else if (sentiment === "neutral") {
badge = `<span class="badge badge-ghost">Neutral</span>`;
} else {
badge = `<span class="badge badge-ghost">Unsure</span>`;
}
var cardElement = document.getElementById("card-" + cardIndex);
cardElement.innerHTML = `
<div class="card bg-base-100 shadow-xl w-full">
<div class="m-4 flex flex-col gap-2">
<div>${sentence}</div>
<div class="flex flex-row justify-end">
${badge}
</div>
</div>
</div>
`;
runningInference = false;
}
function setAlert(msg) {
var alertElement = document.getElementById("alert");
alertElement.innerHTML = `
<div class="alert alert-error">
<svg xmlns="http://www.w3.org/2000/svg" class="stroke-current shrink-0 h-6 w-6" fill="none" viewBox="0 0 24 24"><path stroke-linecap="round" stroke-linejoin="round" stroke-width="2" d="M10 14l2-2m0 0l2-2m-2 2l-2-2m2 2l2 2m7-2a9 9 0 11-18 0 9 9 0 0118 0z" /></svg>
<span class="text-error-content">${msg}</span>
</div>
`;
setTimeout(function () {
alertElement.innerHTML = "";
}, 3000);
}
Key Value Explorer
For this, we install use a pre-made template by pointing to the templates GitHub repository:
$ spin templates install --git https://github.com/fermyon/spin-kv-explorer
Then, we again use spin add to add the new component. We will name the component kv-explorer):
$ spin add kv-explorer -t kv-explorer
Application Manifest
As shown below, the Spin framework has done all of the scaffolding for us:
spin_manifest_version = 2
[application]
name = "sentiment-analysis"
version = "0.1.0"
authors = ["Your Name <your-name@example.com>"]
description = "A sentiment analysis API that demonstrates using LLM inferencing and KV stores together"
[[trigger.http]]
route = "/api/..."
component = "sentiment-analysis"
[component.sentiment-analysis]
source = "target/wasm32-wasip1/release/sentiment_analysis.wasm"
allow_outbound_hosts = []
ai_models = ["llama2-chat"]
key_value_stores = ["default"]
[component.sentiment-analysis.build]
command = "cargo build --target wasm32-wasip1 --release"
watch = ["src/**/*.rs", "Cargo.toml"]
[[trigger.http]]
route = "/..."
component = "ui"
[component.ui]
source = { url = "https://github.com/fermyon/spin-fileserver/releases/download/v0.3.0/spin_static_fs.wasm", digest = "sha256:ef88708817e107bf49985c7cefe4dd1f199bf26f6727819183d5c996baa3d148" }
files = [{ source = "assets", destination = "/" }]
[[trigger.http]]
route = "/internal/kv-explorer/..."
component = "kvv2"
[component.kv-explorer]
source = { url = "https://github.com/fermyon/spin-kv-explorer/releases/download/v0.10.0/spin-kv-explorer.wasm", digest = "sha256:65bc286f8315746d1beecd2430e178f539fa487ebf6520099daae09a35dbce1d" }
allowed_outbound_hosts = ["redis://*:*", "mysql://*:*", "postgres://*:*"]
# add or remove stores you want to explore here
key_value_stores = ["default"]
spin_manifest_version = 2
[application]
authors = ["Your Name <your-name@example.com>"]
description = "A sentiment analysis API that demonstrates using LLM inferencing and KV stores together"
name = "sentiment-analysis"
version = "0.1.0"
[[trigger.http]]
route = "/api/..."
component = "sentiment-analysis"
[component.sentiment-analysis]
source = "app.wasm"
ai_models = ["llama2-chat"]
key_value_stores = ["default"]
[component.sentiment-analysis.build]
command = "componentize-py -w spin-http componentize app -o app.wasm"
watch = ["*.py", "requirements.txt"]
[[trigger.http]]
component = "kv-explorer"
route = "/internal/kv-explorer/..."
[component.kv-explorer]
source = { url = "https://github.com/fermyon/spin-kv-explorer/releases/download/v0.10.0/spin-kv-explorer.wasm", digest = "sha256:65bc286f8315746d1beecd2430e178f539fa487ebf6520099daae09a35dbce1d" }
allowed_outbound_hosts = ["redis://*:*", "mysql://*:*", "postgres://*:*"]
# add or remove stores you want to explore here
key_value_stores = ["default"]
[component.kv-explorer.variables]
kv_credentials = ":"
[variables]
kv_explorer_user = { required = true }
kv_explorer_password = { required = true }
[[trigger.http]]
route = "/..."
component = "ui"
[component.ui]
source = { url = "https://github.com/fermyon/spin-fileserver/releases/download/v0.3.0/spin_static_fs.wasm", digest = "sha256:ef88708817e107bf49985c7cefe4dd1f199bf26f6727819183d5c996baa3d148" }
files = [{ source = "assets", destination = "/" }]
Building and Deploying Your Spin Application
Note: Running inferencing on localhost (your CPU) is not as optimal as deploying to Fermyon’s Serverless AI (where inferencing is performed by high-powered GPUs). You can skip this spin build --up step and move straight to spin cloud deploy if you:
- a) are using one of the 3 supported models above,
- b) have configured your
spin.tomlfile to explicitly configure the model (as shown above)
Now, let’s build and run our Spin Application locally. (Note: If you are following along with the TypeScript/JavaScript example, you will first need to run npm install. Otherwise, please continue to the following spin command.)
$ spin build --up
$ python3 -m venv venv
$ source venv/bin/activate
$ pip3 install -r requirements.txt
$ spin build --up
Test Locally
# Create a new POST request to localhost
$ curl -vXPOST 'localhost:3000/api/sentiment-analysis' -H'Content-Type: application/json' -d "{\"sentence\": \"Well this is very nice indeed\" }"
{"sentiment":"positive"}
Deploy to Fermyon Cloud
Deploying to the Fermyon Cloud is one simple command. If you have not logged into your Fermyon Cloud account already, the CLI will prompt you to login. Follow the instructions to complete the authorization process.
$ spin cloud deploy
Testing in Fermyon Cloud
# Create a new POST request to your apps URL in Fermyon Cloud
$ curl -vXPOST 'https://abcxyz.fermyon.app/api/sentiment-analysis' -H'Content-Type: application/json' -d "{\"sentence\": \"Well this is very nice indeed\" }"
{"sentiment":"positive"}
Visit Fermyon Cloud UI
Visiting your apps URL will produce a User Interface (UI) similar to the following.
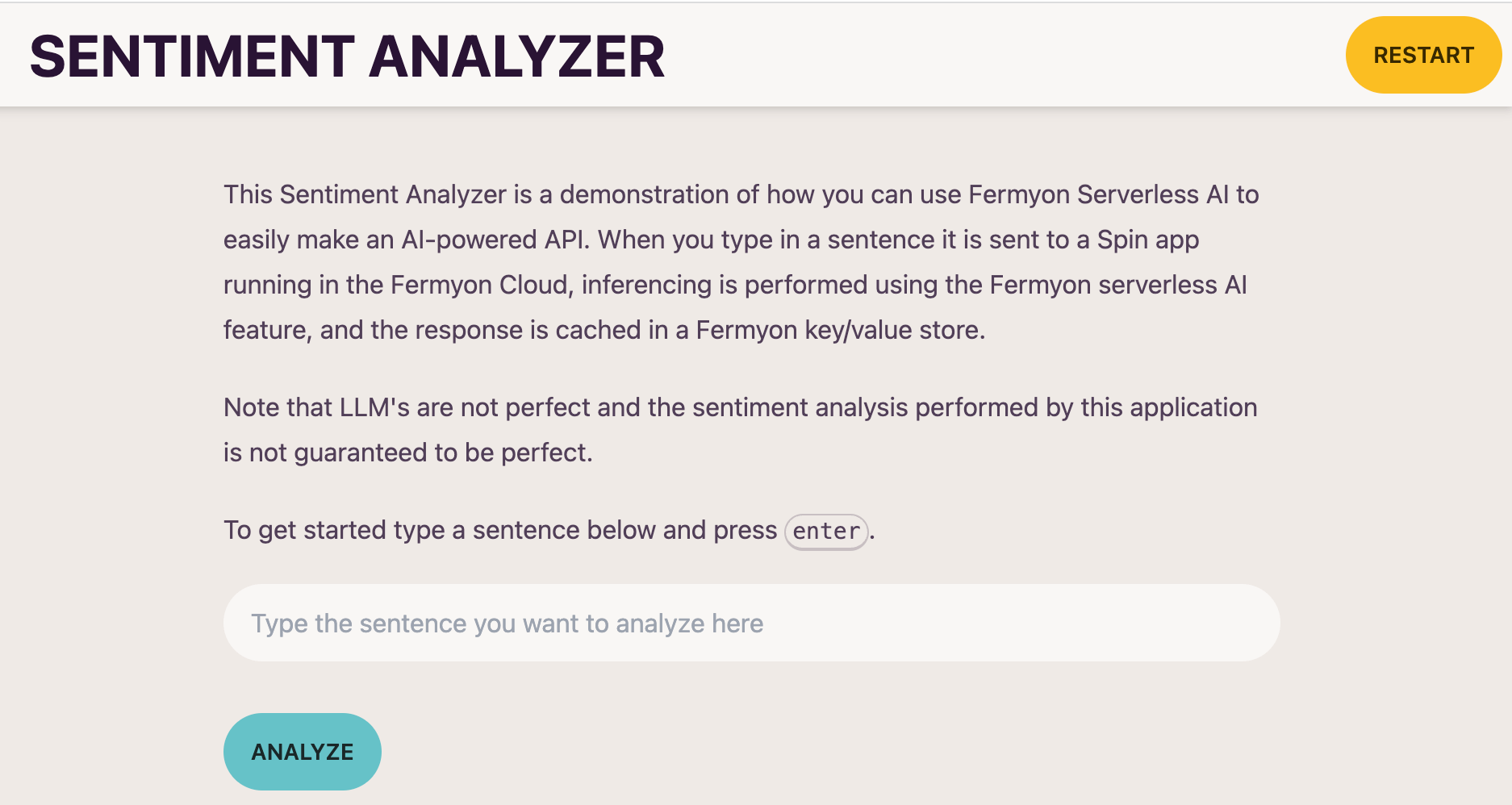
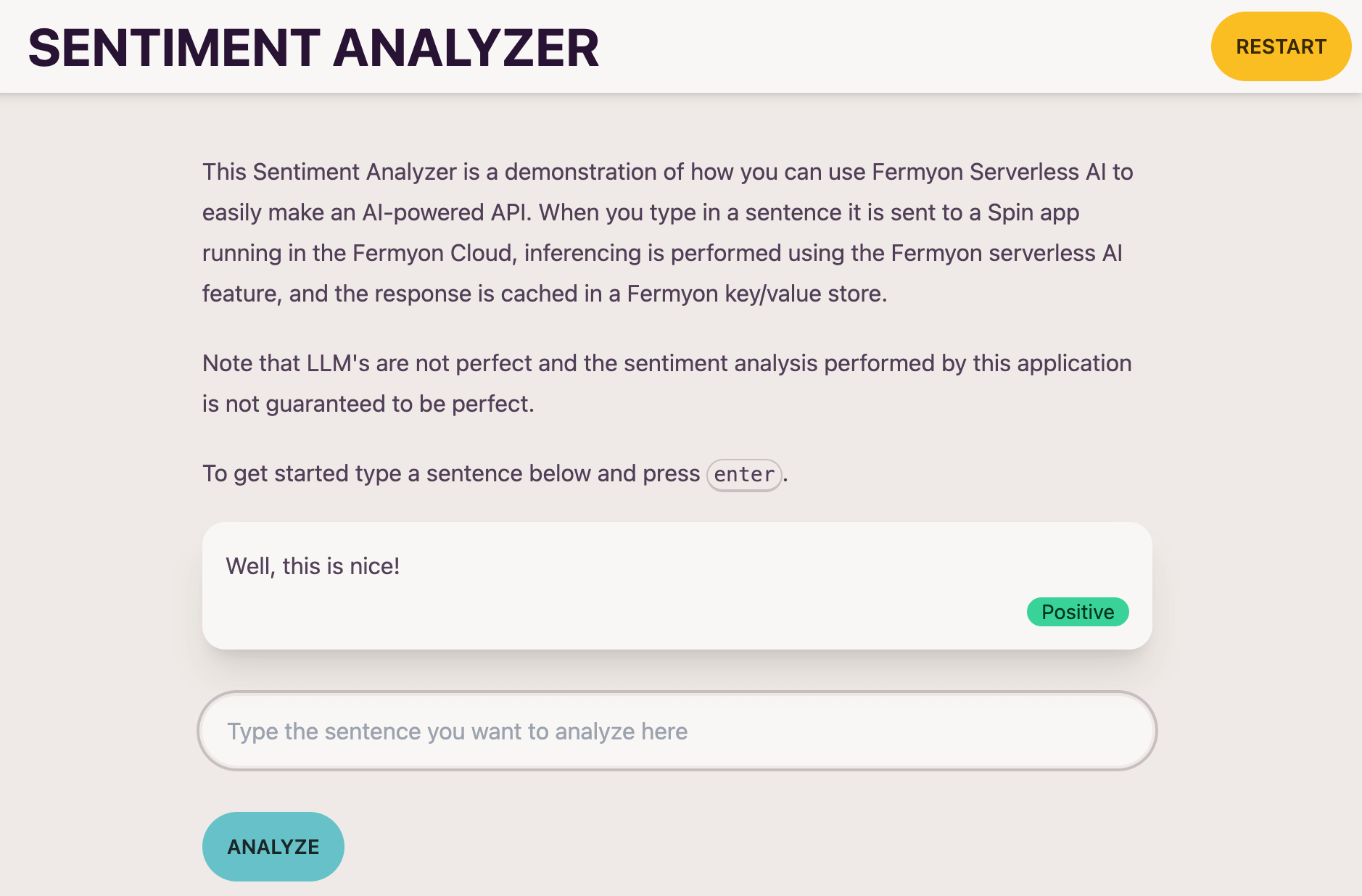
You can type in a sentence, and the UI will respond with the sentiment analysis.
Integrating Custom Domain and Storage
The groundbreaking Fermyon Serverless AI introduces a revolutionary addition to the full-stack developer’s arsenal. You can now seamlessly integrate the Fermyon SQLite Database, Key-Value Storage, and even your Fermyon Cloud Custom Domains with the launch of your very own advanced AI-enabled serverless applications.
Conclusion
We want to get feedback on the Serverless AI API. We are curious about what models you would like to use and what applications you are building using Serverless AI. Let us know what you need, and how Fermyon’s Serverless AI could potentially help solve a problem for you. We would love to help you write your new Serverless AI application.
Next Steps
- Try the numerous Serverless AI examples in our GitHub repository called ai-examples.
- Contribute your Serverless AI app to our Spin Hub.
- Ask questions and share your thoughts in our Discord community.